

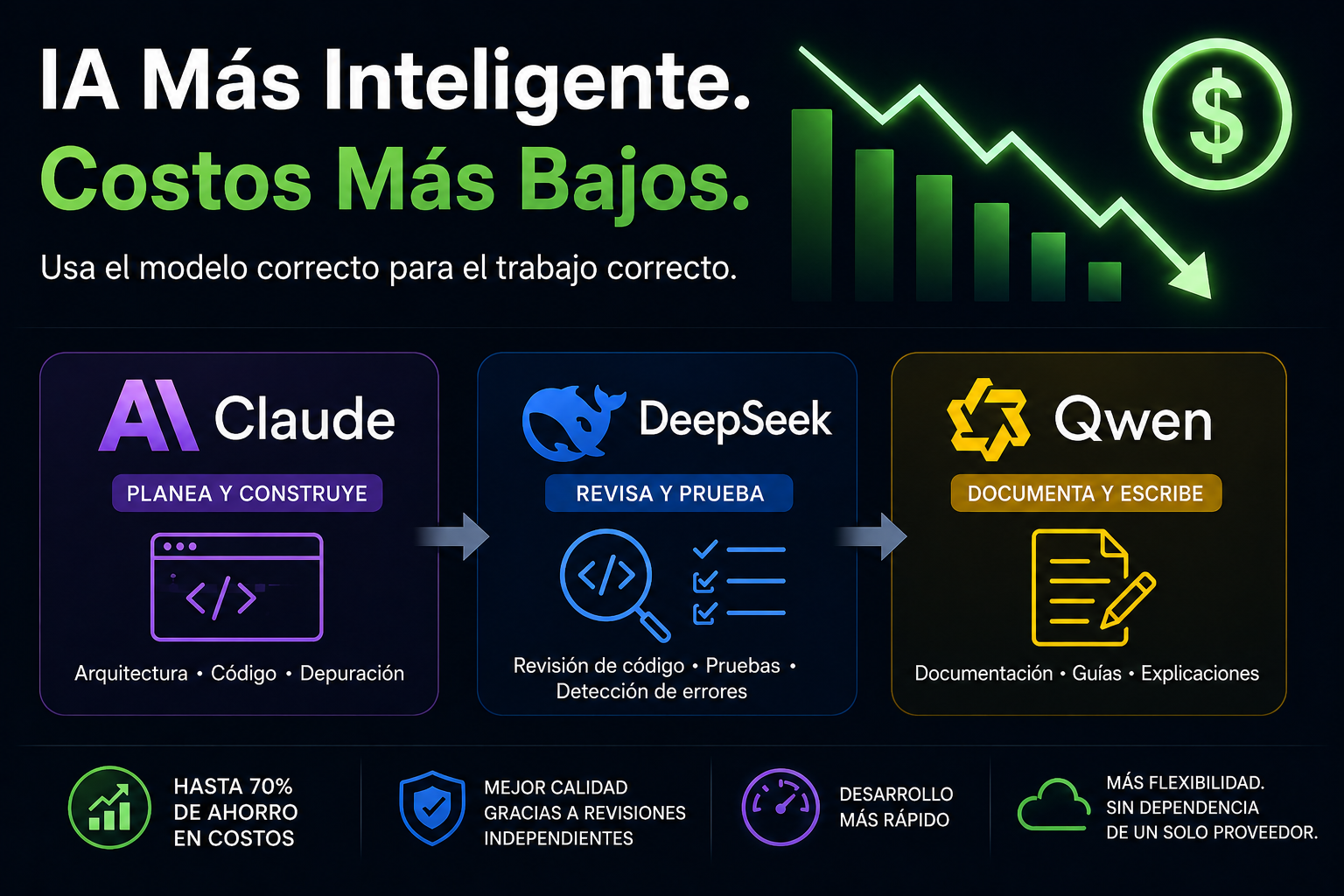
Si tu equipo está enviando cada tarea de programación a un único modelo de IA de primer nivel, es muy probable que estés pagando de más, posiblemente bastante. La solución no es cambiarte a un modelo más barato y cruzar los dedos. Es algo más inteligente: usar el modelo adecuado para cada trabajo.
Esta es la misma lógica que ya usa cualquier buen líder de equipo de ingeniería. No le pides al arquitecto principal que tome las notas de la reunión, ni le entregas una revisión de seguridad crítica al practicante recién llegado. Los modelos de IA funcionan mejor de la misma forma. En este artículo vamos a desglosar una estrategia multimodelo práctica que combina Claude, DeepSeek y Qwen para recortar costos sin sacrificar la calidad del resultado.
No necesitas un doctorado. Entremos en materia.
Primero, la versión sencilla
Imagina que manejas la cocina de un restaurante ajetreado. Tienes un chef principal, unos cuantos cocineros de línea y un equipo de preparación.
- El chef principal diseña el menú y se encarga de los platos más delicados.
- Los cocineros de línea ejecutan y revisan los platos unos de otros.
- El equipo de preparación pica verduras y etiqueta los recipientes.
Si les pagaras a todos el sueldo de un chef principal —incluso a quien pica la cebolla— te quedarías sin plata muy rápido. Y, la verdad, la comida no sabría mejor.
Los modelos de IA son tu personal de cocina. Algunos son especialistas costosos. Otros son rápidos, económicos y excelentes para el trabajo de alto volumen. Una estrategia multimodelo simplemente significa poner a cada uno donde brilla en lugar de pagar tarifas premium por tareas que no requieren razonamiento premium.
El costo oculto de «un solo modelo para todo»
Un flujo de trabajo típico de software se ve así:
- Arquitectura y planeación
- Escribir el código en sí
- Revisión de código
- Escribir pruebas
- Documentación
- Depuración y refactorización
Muchos equipos pasan todo esto por un único modelo premium. Funciona, pero la cuenta crece sin que te des cuenta. La documentación, los esqueletos de pruebas y las revisiones rutinarias son tareas de alto volumen, y consumen tokens costosos que podrían costar una fracción en otro lado.
El objetivo no es «usar el modelo más barato». El objetivo es: no malgastar tu modelo más capaz (y más costoso) en trabajo que uno más económico maneja igual de bien.
Conoce los tres modelos (y para qué sirve cada uno)
Esta es la alineación a mediados de 2026, con precios aproximados de API por millón de tokens. (Los precios cambian rápido; revisa siempre las páginas oficiales de precios antes de armar tu presupuesto.)
| Modelo | Mejor para | Entrada / Salida (por 1M de tokens) | Estilo |
|---|---|---|---|
| Claude (Opus 4.8 / Sonnet 4.6) | Arquitectura, razonamiento sobre bases de código grandes, refactorizaciones de múltiples archivos, depuración compleja | Opus ~$5 / $25 · Sonnet ~$3 / $15 | El arquitecto senior |
| DeepSeek (V4 Flash / V4 Pro) | Revisión de código, algoritmos, detección de errores, generación de pruebas | Flash ~$0.14 / $0.28 · Pro ~$0.44 / $0.87 | El revisor agudo e incansable |
| Qwen (serie 3.6 / 3.7) | Documentación, explicaciones, andamiaje de pruebas, bases de conocimiento | Flash ~$0.19 / $1.13 · Plus ~$0.50 / $3.00 | El escritor rápido y fluido |
Algunas cosas que vale la pena saber:
- Claude sigue liderando en razonamiento profundo sobre bases de código grandes y desordenadas. Cuando un cambio toca decenas de archivos interconectados, ahí es donde el razonamiento premium se gana su sueldo.
- DeepSeek se ha convertido en el campeón de relación precio-rendimiento para el trabajo de programación puro, con muy buenos resultados en benchmarks como SWE-bench, a aproximadamente 1/30 del costo de los modelos premium. Además es de pesos abiertos (licencia MIT), así que puedes autoalojarlo si quieres.
- Qwen (de Alibaba) es multimodal, trae una ventana de contexto enorme y produce prosa limpia y fácil de leer, ideal para documentación. Muchos modelos Qwen también son de pesos abiertos, así que el despliegue local es una opción.
Una aclaración rápida: analogía vs. realidad
Piensa en los tres como en un hospital. Claude es el cirujano especialista que llamas para el caso complicado. DeepSeek es el médico tratante con experiencia que detecta en la ronda lo que a otros se les pasa. Qwen es el residente excelente que redacta notas claras y completas de los pacientes. Necesitas a los tres, pero jamás pagarías tarifa de cirujano por escribir notas en la historia clínica.
Entonces… ¿cuál es mejor para el trabajo agéntico?
Esto merece su propia respuesta, porque «escribir código» y «ejecutar un agente autónomo» no son la misma habilidad. Un agente no solo responde una vez: planea, llama a herramientas, lee el resultado, corrige sus propios errores y sigue avanzando a lo largo de muchos pasos. Piénsalo menos como una calculadora y más como un practicante al que puedes dejar solo con una tarea: la pregunta no es «¿puede escribir el código?» sino «¿puede mantenerse en el camino durante 30 pasos sin perderse?»
Esa confiabilidad de largo aliento es donde los modelos realmente se diferencian.
La respuesta corta
- Agente más capaz → Claude. A mediados de 2026, Claude Opus 4.8 lidera entre los modelos disponibles públicamente en programación agéntica y «uso del computador» (manejar una terminal, un navegador o un IDE), con la mejor confiabilidad paso a paso y la mejor capacidad de recuperación cuando una tarea se complica. Si le vas a entregar a un agente un ticket difícil y abierto y quieres que lo termine, esta es la apuesta más segura. (El modelo de vanguardia en vista previa de investigación de Anthropic encabeza las tablas agénticas, pero no está disponible para el público general.)
- Mejor agente de pesos abiertos → DeepSeek V4 Pro. Es la opción destacada en relación costo-calidad para los ciclos agénticos que puedes ejecutar a gran escala, y como es de pesos abiertos, puedes autoalojarlo. Excelente cuando necesitas buena autonomía sin cuentas premium de API.
- Mejor para ejecutar muchos agentes económicos → Qwen (3.6 Plus / 3.7 Max). Los modelos más nuevos de Qwen están hechos para cargas de trabajo centradas en agentes, manejan las llamadas a herramientas de forma confiable en sesiones largas y son lo suficientemente económicos como para desplegar decenas de subagentes en paralelo. Ideales para arquitecturas de «enjambre», donde se ejecutan a la vez montones de tareas pequeñas y bien definidas.
Una advertencia importante
Los puntajes en benchmarks agénticos dependen muchísimo del armazón (el andamiaje alrededor del modelo: cómo se exponen las herramientas, cómo se le devuelven los errores, cuántos reintentos tiene), no solo del modelo en sí. El mismo modelo puede verse brillante en un framework de agentes y mediocre en otro. Así que toma las tablas de clasificación como punto de partida y luego pruébalo con tus tareas en tu configuración.
Regla práctica: modelo premium (Claude) para las tareas difíciles y autónomas de «resuélvelo tú»; pesos abiertos (DeepSeek) cuando quieras buena autonomía a bajo costo; Qwen cuando quieras ejecutar muchos agentes livianos en paralelo.
El flujo de trabajo multimodelo en la práctica
Así podría fluir una sola funcionalidad a través del equipo:
Paso 1 — Planear con Claude
Aliméntale a Claude tus requisitos, la arquitectura existente y las restricciones. Te devuelve un diseño técnico y un desglose de tareas. Esto es razonamiento de alto valor, así que el precio premium se justifica.
Paso 2 — Construir con Claude
Usa Claude (o Claude Code) para la implementación central, sobre todo cualquier cosa que abarque múltiples archivos o lógica heredada.
Paso 3 — Revisar con DeepSeek
En lugar de pedirle a Claude que califique su propia tarea, entrégale el pull request a DeepSeek:
«Revisa este PR en busca de cuellos de botella de rendimiento, problemas de seguridad y casos límite.»
Obtienes una segunda opinión independiente por una fracción mínima del costo, igual que en los equipos reales, donde un ingeniero distinto revisa el código antes de publicarlo.
Paso 4 — Documentar con Qwen
Apunta Qwen al código terminado:
«Genera documentación para desarrolladores y un changelog para estos endpoints REST.»
Documentación limpia y lista para publicar, sin gastar tokens premium.
Paso 5 — Revisión final con Claude
Solo para lanzamientos críticos, trae de vuelta a Claude para una validación final. Razonamiento premium, reservado para los momentos que de verdad importan.
Cómo se ve esto en código
No necesitas nada sofisticado para enrutar tareas de manera inteligente. Un simple «enrutador de modelos» —una función que elige un modelo según el tipo de tarea— te genera casi todo el ahorro:
# Un enrutador de modelos minúsculo: asigna la tarea al modelo adecuado
MODEL_FOR_TASK = {
"architecture": "claude-opus-4-8", # razonamiento profundo
"implementation": "claude-sonnet-4-6", # código sólido, menor costo
"code_review": "deepseek-v4-pro", # revisor barato y fuerte
"test_gen": "deepseek-v4-flash", # alto volumen, bajo costo
"documentation": "qwen3.6-flash", # escritor rápido y fluido
}
def pick_model(task_type: str) -> str:
# Recurre a un valor por defecto balanceado si la tarea es desconocida
return MODEL_FOR_TASK.get(task_type, "claude-sonnet-4-6")
# Uso
model = pick_model("code_review") # -> "deepseek-v4-pro"
Esa es toda la idea. La complejidad está en decidir el mapeo; la implementación es una consulta a un diccionario. Herramientas como OpenRouter o un envoltorio interno sencillo facilitan aún más intercambiar modelos detrás de una sola interfaz.
La plata: un ejemplo realista (ilustrativo)
Digamos que tu equipo usa cerca de 50 millones de tokens al mes en todas las tareas de programación. Aquí va una comparación aproximada. Los números son ilustrativos —los costos reales dependen de tu proporción de entrada/salida y del uso de caché—, pero lo que importa es la tendencia.
| Tarea | Tokens mensuales | Todo premium (Claude Opus) | Con enrutamiento inteligente | Costo con enrutamiento inteligente |
|---|---|---|---|---|
| Arquitectura + desarrollo central | 20M | Opus → ~$180 | Opus/Sonnet | ~$180 |
| Revisiones de código | 10M | Opus → ~$90 | DeepSeek | ~$2 |
| Documentación | 10M | Opus → ~$90 | Qwen | ~$5 |
| Generación de pruebas | 10M | Opus → ~$90 | DeepSeek | ~$2 |
| Total | 50M | ≈ $450/mes | — | ≈ $189/mes |
Eso es aproximadamente una reducción del 58%, sin una caída relevante en la calidad, porque el modelo premium sigue haciendo todo el trabajo que de verdad necesita razonamiento premium. En distintos tipos de carga, los equipos suelen reportar ahorros en el rango del 30% al 70%. Si le sumas el almacenamiento en caché de prompts (hasta ~90% de descuento en contexto repetido), puedes llevarlo aún más lejos.
No se trata solo de costos
Ahorrar plata es el titular, pero una configuración multimodelo trae otras ventajas:
- Mejor calidad gracias a las segundas opiniones. Un modelo revisor que no escribió el código tiene más probabilidades de detectar sus puntos ciegos, por la misma razón por la que las personas no revisan sus propios pull requests.
- Menos dependencia de un solo proveedor. Repartir el trabajo entre varios proveedores te da flexibilidad, poder de negociación y un plan B si un servicio se cae o sube los precios.
- Más paralelismo. Mientras Claude construye la siguiente funcionalidad, DeepSeek puede revisar la anterior y Qwen documenta la de más atrás. Menos espera, entregas más rápidas.
Asignación de modelos recomendada
Un punto de partida práctico que puedes adaptar a tu stack:
- Arquitectura de sistemas y refactorizaciones grandes → Claude
- Depuración compleja entre archivos → Claude
- Revisión de código rutinaria → DeepSeek
- Generación de pruebas → DeepSeek (o Qwen para casos simples)
- Documentación, referencias de API, base de conocimiento → Qwen
- Revisión de seguridad → DeepSeek para la primera pasada, Claude para la decisión final
- Tareas de agente difíciles y autónomas → Claude (la mayor confiabilidad de largo aliento)
- Agentes sensibles al costo o en paralelo → DeepSeek V4 Pro, o Qwen para correr una flota
- Validación final del lanzamiento → Claude
Empieza migrando un solo tipo de tarea: la revisión de código y la generación de pruebas suelen ser los puntos más limpios para arrancar. Córrelo en paralelo con tu modelo actual durante unos días, compara los resultados y cámbiate solo cuando estés satisfecho. Mantén una «salida de emergencia» que reenvíe los resultados de baja confianza a un modelo premium.
Por qué esto importa justo ahora
2026 ha sido una guerra de precios para los modelos de IA enfocados en programación. Las opciones de pesos abiertos de DeepSeek y Alibaba ahora quedan a un par de puntos de los modelos premium en los benchmarks de código, a una fracción mínima del precio. Al mismo tiempo, la IA pasó de ser un «autocompletado que está bueno tener» a una parte central de cómo se construye el software. Esa combinación significa que la forma en que enrutas el trabajo ya es un rubro real del presupuesto, no un error de redondeo. Los equipos que tratan la selección de modelos como una decisión de ingeniería —y no como algo por defecto— sencillamente van a construir más por menos.
La pregunta más inteligente para los líderes de ingeniería no es «¿Cuál es el mejor modelo?». Es:
«¿Cuál modelo es mejor para esta tarea específica?»
Puntos clave
- No uses un solo modelo para todo. Asigna el modelo a la tarea, como si armaras un equipo.
- Claude se gana su precio premium en arquitectura, refactorizaciones grandes y depuración difícil.
- DeepSeek es el caballito de batalla rentable para revisión de código, pruebas y caza de errores.
- Qwen escribe documentación y explicaciones rápidas y limpias por muy poco, y corre bien agentes económicos en paralelo.
- Para el trabajo agéntico: Claude es el más confiable para tareas difíciles y autónomas; DeepSeek V4 Pro es la mejor opción de pesos abiertos; recuerda que el armazón importa tanto como el modelo.
- Un simple enrutador de modelos (incluso un diccionario) captura casi todo el ahorro.
- Espera costos de un 30% a un 70% más bajos con calidad similar, y ventajas adicionales en calidad, flexibilidad y velocidad.
- Empieza de a poco: migra un tipo de tarea, córrelo en paralelo y luego expande.
Los precios y las alineaciones de modelos cambian con frecuencia; verifica las tarifas actuales en la página oficial de precios de cada proveedor antes de armar tu presupuesto.



